Research
2023
-
 Convolutional Networks with Oriented 1D KernelsKirchmeyer A., and Deng J.IEEE/CVF International Conference on Computer Vision (ICCV), 2023
Convolutional Networks with Oriented 1D KernelsKirchmeyer A., and Deng J.IEEE/CVF International Conference on Computer Vision (ICCV), 2023In computer vision, 2D convolution is arguably the most important operation performed by a ConvNet. Unsurprisingly, it has been the focus of intense software and hardware optimization and enjoys highly efficient implementations. In this work, we ask an intriguing question: can we make a ConvNet work without 2D convolutions? Surprisingly, we find that the answer is yes – we show that a ConvNet consisting entirely of 1D convolutions can do just as well as 2D on ImageNet classification. Specifically, we find that one key ingredient to a high-performing 1D ConvNet is oriented 1D kernels: 1D kernels that are oriented not just horizontally or vertically, but also at other angles. Our experiments show that oriented 1D convolutions can not only replace 2D convolutions but also augment existing architectures with large kernels, leading to improved accuracy with minimal FLOPs increase. A key contribution of this work is a highly-optimized custom CUDA implementation of oriented 1D kernels, specialized to the depthwise convolution setting. Our benchmarks demonstrate that our custom CUDA implementation almost perfectly realizes the theoretical advantage of 1D convolution: it is faster than a native horizontal convolution for any arbitrary angle. Code is available at this https URL: https://github.com/princeton-vl/Oriented1D.
-
 Zero-shot Image to 3D using Diffusion modelsKirchmeyer A., Duggal S., and Pathak D.Independent Study Spring 2023, 2023
Zero-shot Image to 3D using Diffusion modelsKirchmeyer A., Duggal S., and Pathak D.Independent Study Spring 2023, 2023Text-to-3D methods have made significant strides in the past year, by leveraging the power of diffusion models to optimize the representation of 3D shapes conditioned on a text prompt. These methods can be used for 3D asset creation and find applications in the animation and gaming industries. Current state-of-the-art open-source methods have difficulty getting cross-view consistency, leading to inconsistent depths and the so-called multiple Janus head problem. To tackle this challenge, we introduce a diffusion model trained on novel view synthesis and conditioned on previous views. To overcome the lack of 3D data, we design our approach to be category-free by generating sparse novel views of the input image and augmenting these views with inpainting using diffusion models.


2022
-
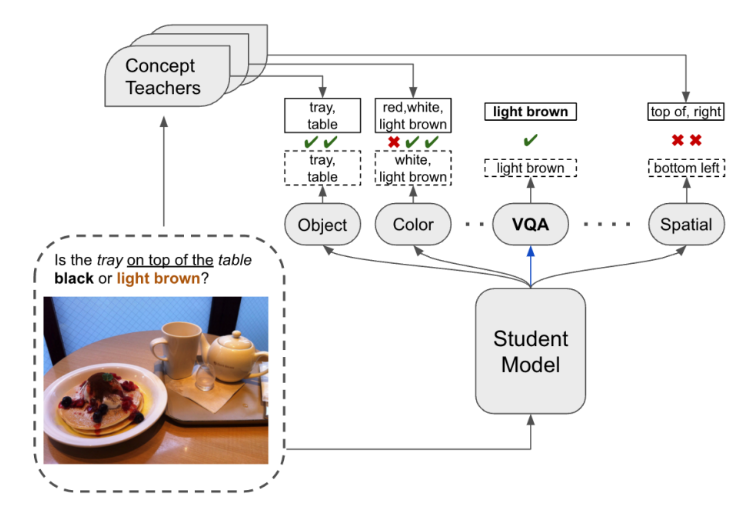 Multi-Modal Concept Learning using Auxiliary Learning and Diffusion modelsKirchmeyer A., and alCMU 11-777 Multi-Modal Machine Learning Fall 2022 Course, 2022
Multi-Modal Concept Learning using Auxiliary Learning and Diffusion modelsKirchmeyer A., and alCMU 11-777 Multi-Modal Machine Learning Fall 2022 Course, 2022Recent developments, especially in transformer-based models, have led to impressive progress on multimodal tasks such as visual question-answering. However, it is still unclear whether these large pretrained models know the concepts needed to reason about the problem and whether they can combine these concepts to produce predictions instead of simply relying on surface patterns in the data. We study the performance of multimodal models, specifically ViLT, on VQA dataset Visual7W, and implement 3 approaches through the lens of our concept-driven framework. We find that concept information can be useful as auxiliary information via multitask learning, their latent representations can be useful in uncovering latent concepts, and causal generative augmentation of images can increase the robustness of ViLT towards conceptual variations.
